| Release of training and dev data | April 20th, 2022 |
| Release of test data at the repo. | July 1th, 2022 |
| Result submission deadline | July 7th, 2022 |
| System paper submission deadline | September 7th, 2022 |
| Paper notification | October 9th, 2022 |
| Camera-ready version due | October 16, 2022 |
Note that system paper submission follows the paper submission policy in WMT, please see the section of paper submission information in WMT homepage for more details.
Computer-aided translation (CAT), which leverages the advantages of MT systems to help human translators, attracts the attention of researchers. However, research progress in CAT is slower than in automatic MT. One of the main reasons is that almost no public shared tasks are available for CAT research. The lack of such shared tasks has hindered researchers from making continuous progress in this area. Therefore, we organize such a shared task in WMT 2022, to push forward the research on CAT. Generally, the task is called Word-Level AutoCompletion (WLAC), which aims to predict a target word given a source sentence, translation context and a human typed character sequence. WLAC plays an important role in a CAT system in enhancing translation efficiency.
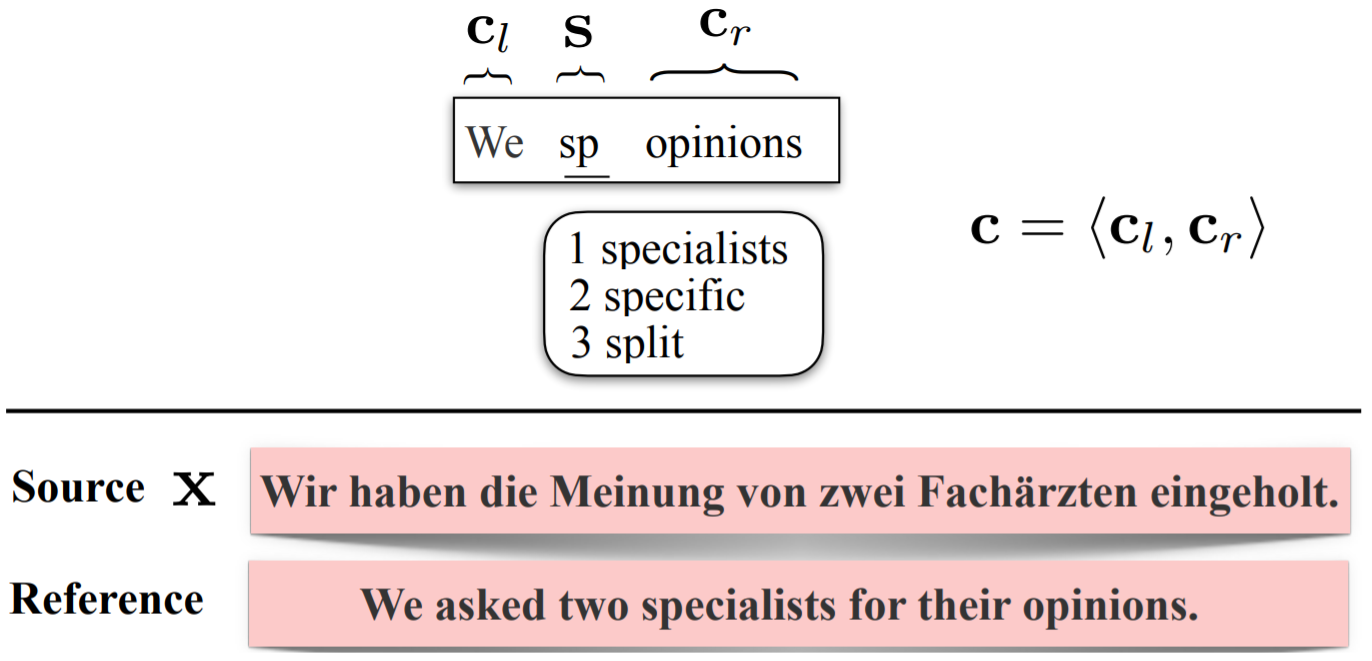
Suppose x = (x1, x2, . . . , xm) is a source sequence, s = (s1, s2, . . . , sk) is a sequence of human typed characters, and a translation context is denoted by c = (cl, cr ), where cl= (cl,1, cl,2, . . . , cl,i), cr = (cr,1, cr,2, . . . , cr,j ). The translation pieces cland crare on the left and right hand side of s, respectively. This basic idea about WLAC task is shown in Fig 1, where the translation context c includes the left context cl and right context cr, underlined text “sp” is the human typed characters s and the words in the rounded rectangles are word-level autocompletion candidates. Formally, given a source sequence x, typed character sequence s and a context c, the word-level autocompletion (WLAC) task aims to predict a target word w which is to be placed in the middle between cland crto constitute a partial translation. Note that in the partial translation consisting of cl, w and cr, w is not necessary to be consecutive to cl,i or cr,1. For example, in Figure 1, cl = ("We", ), cr = ("opinions"), s = ("sp", ), the WLAC task is expected to predict w = "specialists" to constitute a partial translation "We ··· specialists ··· opinions ", where "···" represents zero, one, or more words (i.e., the two words before and after it are not necessarily consecutive).
To make the task more general in real-world scenarios, the assumption is made that the left context cl and right context cr can be empty, which leads to the following four types of context:
ATTENTION!! Test datasets are available at the repo. Participants must use only the bilingual data provided in train/dev/test.
Note that pretrained language models such as BERT are allowed as well as additional monolingual data.Human Evaluation: Given a source sentence x, context c and a typed sequence s, there would be multiple ground-truth words w sufficing to the constraint of s, especially for a short s. However only a single of them is provided in the realistic test datasets, and hence automatic evaluation may lead to some limitations. As a result, we will additionally hire some professional translators for human evaluation by manually checking whether a predicted word is true or not.
For any further questions or suggestions, please drop an email to Lemao Liu.
Supported by TBA.